无人车或者说自动驾驶是人类科技发展的集大成者,它不是凭空出现的。无人车的理论依据已经非常完备,这就是机器人理论,无人车可以看作轮式机器人。
过去近50年,机器人的理论体系已经非常完备,也就是说无人车的理论体系也很完备。经过这50年的验证,尤其是自2007年的DARPA大赛后,轮式机器人理论在无人车上也经过了近10年的验证。实践证明,轮式机器人的理论体系非常适合无人车,也是无人车最合适采用的理论体系,重新再设计一套理论体系至少需要数十年的历程。
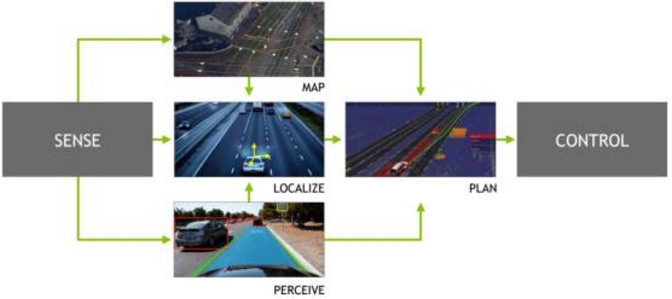
无人车的框架并不复杂,包括环境感知、定位、状态与轨迹估算、路径规划、轨迹规划、执行控制。
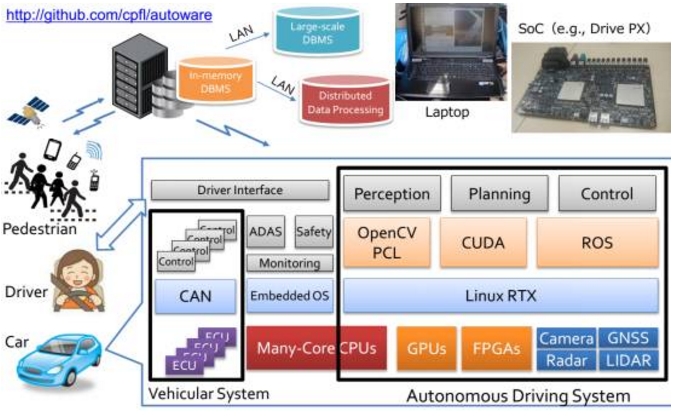
视觉感知部分的软件层主要是OpenCV、还有CUDA,激光雷达则需要PCL,规划方面与控制执行主要是ROS系统,操作系统则是以Linux为基础,底层则是Autosar。
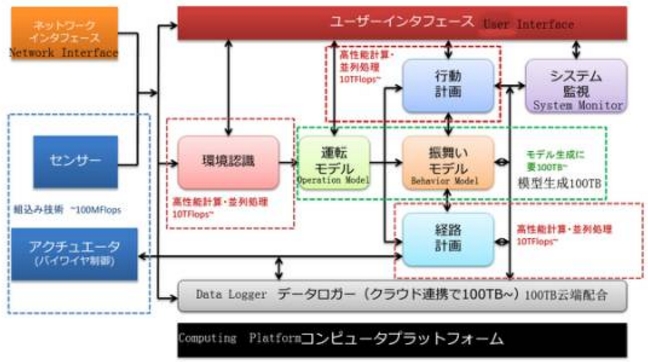
上图是英特尔对未来无人车架构的设计,运算量惊人,感知、路径规划(主要是全局路径规划和避障规划)、行为分析与决策(Behavior Planning)三部分都需要10TFLOPS的运算能力。实际上单用路径规划已经可以保证无人车的安全,但这时无人车只能像刚拿驾照的驾驶员,应变能力比较差。目前阶段无人车能做到新手上路的水平就已经不错了。
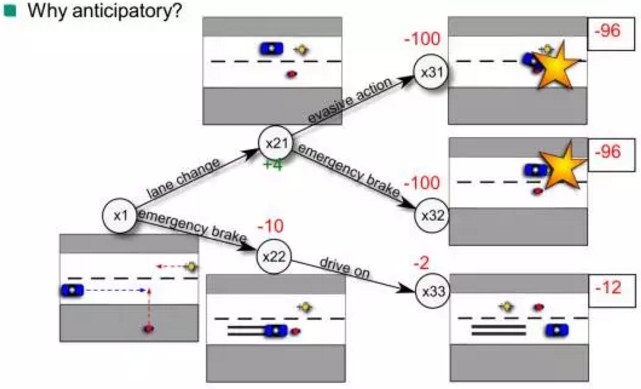
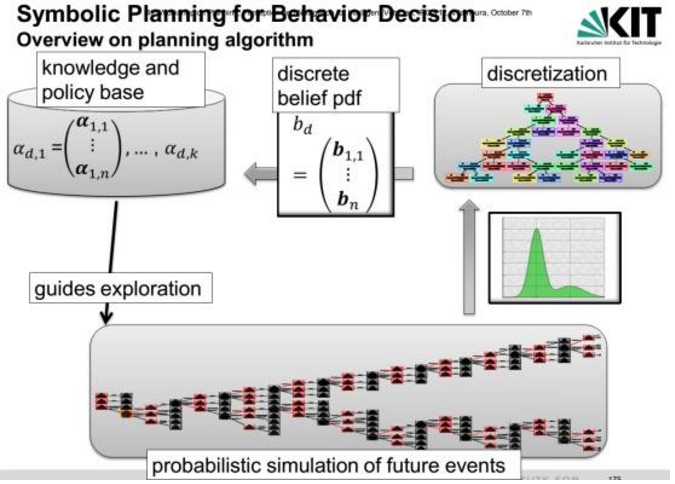
上图为几种行为规划的对比。Behavior Planning的算法体系如下。
目前浮点运算能力最强的处理器是英伟达的Tesla P100,拥有3840个FP32单精度、1920个FP64双精度CUDA核心,单、双精度浮点性能分别高达10.6TFlops、5.3TFlops。与之配合的内存也是非常顶级的4096-bit 16GB HBM2高带宽显存。一套Tesla P100大约1.1万美元。低端一点的有双芯的Tesla K80单精度性能8.74TFLOPS,双精度性能2.91TFLOPS,单芯的Tesla K40单精度性能5TFLOPS,双精度性能也有1.66TFLOPS。K80要价5000美元。
除了英伟达还有英特尔的Knights Landing Xeon Phi。14nm工艺,最多72核288线程,TDP功耗245W,集成16GB eDRAM缓存,,单精度浮点性能3TFLOPS,双精度浮点性能超过1TFLOPS,并可选配Fabric芯片,售价6254美元。

上图为英伟达的Drive PX2,无人车时代同样也是CPUs+GPU的配置,GPU负责并行计算的加速。其框架图如下:
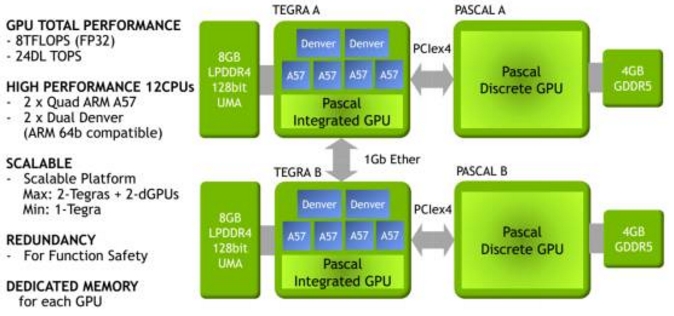
英伟达这一代的Tegra代号为Parker,是一款SoC。

整体电路图如下:
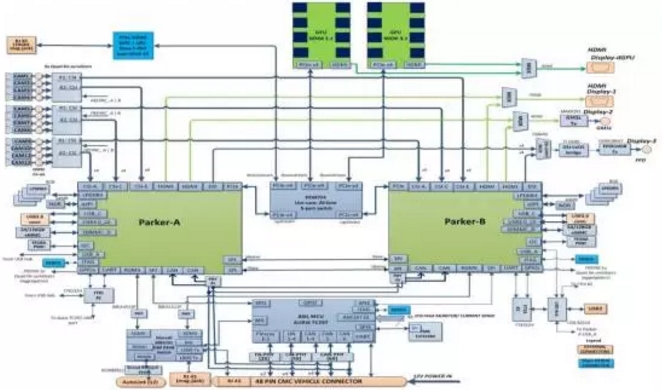
Driver PX2的主要ASIC有Avago的PEX8724(24-lane,6-port,第三代 PCIe Gen交换机)用于两块Parker之间的互联。英伟达还有大杀器Nv-Link,不过美国政府禁止出口Nv-Link给中国,威力太大了,凑合用PCIe吧。以太网的收发交换用Marvell的88E6321。还有一片英特尔收购的Altera提供的FPGA,用于执行实时操作系统。FPGA的型号为Cyclone V 5SCXC6,是Altera的顶级产品,逻辑运算为110K,注册器达166036。最后还有一款英飞凌的AURIX TC 297 MCU做安全控制,据说可以让PX2达到ASIL C级水平,这就远比高通领先了。 还有博通的BCM89811低功耗物理层收发器(PHY),使用BroadR-Reach车载以太网技术,在单对非屏蔽双绞线上的传输速率可达100Mbps。外围芯片还有FT4232H,做USB转4路UART。还有Parker的PMIC,由德州仪器提供。美信的MAX9291 GMSL串行器将HDMI输入转换为吉比特多媒体串行链路(GMSL)输出。
英特尔对未来无人车运算能力的预测更加惊人,英特尔预测到2025年无人车的运算能力高达100TFLOPS,听起来相当夸张。

英特尔预测的根据是未来无人车将采用4个8K级的摄像头,这将导致数据流量高达215Gbps。

这显然不大可能,如果是16:9画幅的话,8K级摄像头的像素达3300万,而目前汽车上130万像素都相当少见,主流还是30万像素,如此高的像素对深度学习之类的应用并无加分,但会导致成本大增,运算量大增以致于整体成本超过5年后的激光雷达。并且摄像头这种被动型传感器受环境影响太大,且改进的空间非常有限,改进的成本太高。激光雷达属于主动型传感器,受环境影响小,改进空间巨大,特别是针对雨雪这样的噪音分布比较均匀且单一的环境,在算法上做改进可以基本解决问题,未来无人车将以激光雷达为核心,摄像头为冗余的传感器配置。
无人车的功能安全鲜有人提及,无人车这套驾驶脑系统自然要达到ASIL D级水准,因为这是和安全密切相关的。
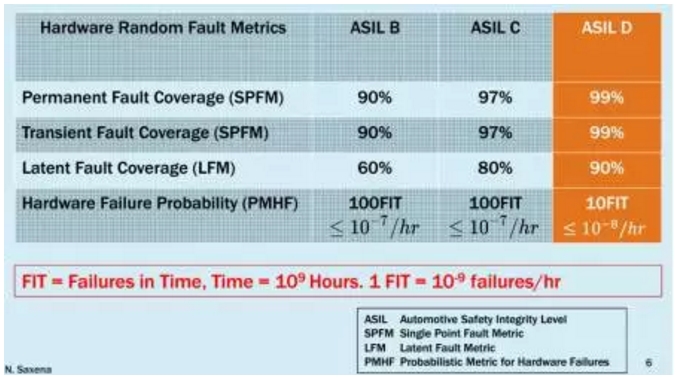
要达到ASIL D级可是相当困难的,要做到1亿小时只有10次失效,也就是1141.5年失效1次。芯片要做到ASIL D通常是建置较大的Cortex-A CPU,包括其高速缓存作为锁步双核心设计,用一种以较小CPU为ASIL-D应用设计安全MCU。显然这会增加成本,而对于GPU则无法实现冗余。最简便的方法就是多提供一个备用的ECU,并在主路径处于安全模式时使用第二个运算路径。由于重复进行操作,使得这样的系统成本较大,而且,除了需要更大的空间外,还会导致更高的功耗。由于控制ECU通常也对于冷却带来限制,可用的功率预算通常低于20瓦。
如何在失效时迅速转换到另一个系统这种思路是不正确的,因为失效的瞬间可能就没命了,要尽量避免失效而不是失效后怎么应对,或者说尽量在系统可能失效前换到另外一个系统,这就牵涉到统计学的马尔科夫链Markov Chain。
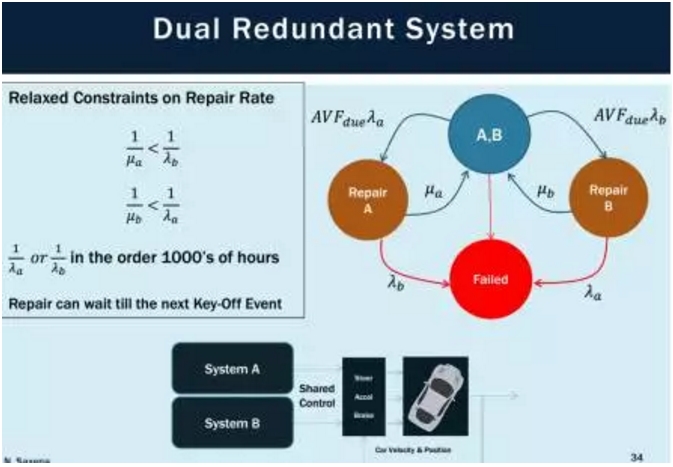
目前这块的研究比较少,特别是软件领域的失效机制。
无人车相比ADAS时代,在整体电子架构上也有比较大的变化。
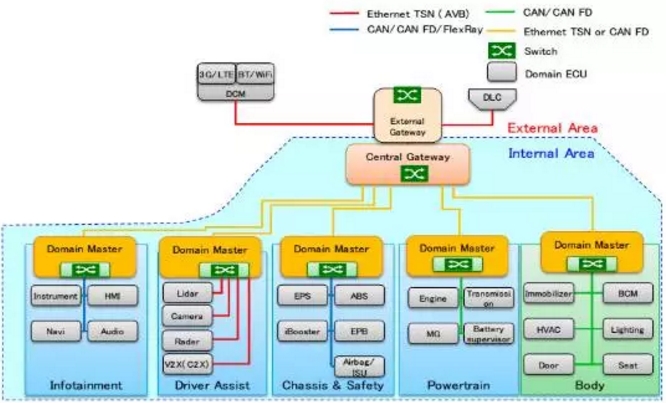
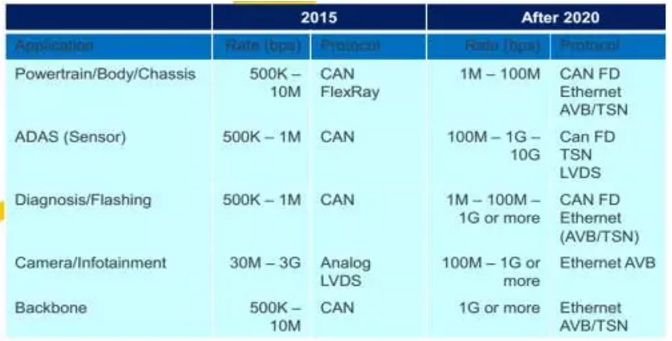
将全面采用域控制器和中央网关的设计,一来是提高运算资源效率,降低成本。二是保证网络安全,不受外来威胁。这种设计和高带宽传感器(未来无人车很有可能用4个64线激光雷达)要求使用新的总线体系,也就是TSN(Time-Sensitive Networking),目前车内以太网的EAVB标准将在无人车时代演变为TSN,TSN已经在2015年8月启动标准化进程,由原EAVB标准小组IEEE802.1负责。
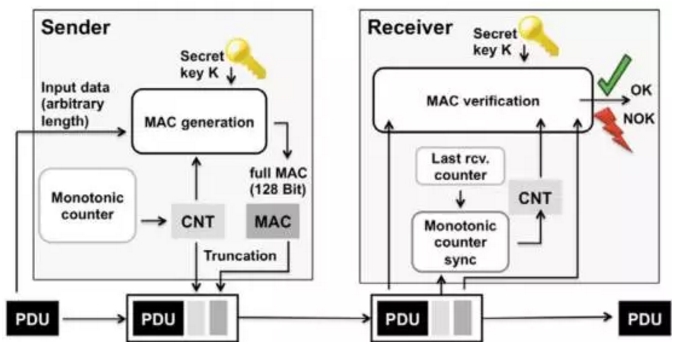
为了应对网络威胁,如黑客干扰无人车,Autosar 4.2.1版本将特别增加Secure On-Board Communication ( “SecOC” ),“SecOC” 采用MAC(Message Authentication Code)验证,验证信息是否为真正的通讯双方所传送,并验证信息在传送过程中是否遗失、掺入或篡改,确保信息的完整性。目前电子金融交易也常用MAC验证,大家完全不用担心无人车被黑客袭击。当然这在ADAS时代也完全适用。
再来说说深度学习芯片,目前深度学习运算大多采用CPU翻译指令,GPU加速的方法来完成,也有用FPGA加速的。GPU处于绝对优势地位,可以说没有GPU,就没有深度学习。为了打破GPU也就是英伟达的垄断,而FPGA通常是ASIC流片前的试验品,于是不少人都在设计针对深度学习的ASIC,试图打破垄断。
不过人类科技已经进入寡头统治时代,用户的黏性(惯性)和寡头构筑的生态圈为后来者树立了高不可攀的门槛。最典型的就是PowerPC架构的消亡,如今x86架构处于绝对垄断地位已经超过10年,x86与Windows构筑的ISA生态圈让x86大者恒大。ARM依靠安卓和苹果则在移动领域构筑了绝对垄断的生态圈,你可以不用ARM的内核,但是ARM的ISA已经成为业内的标准,用户不得不支持,不支持就寸步难行,卖不出去。做一个ISA不是难事,难的是让全球几十亿用户几百亿的设备都支持。这就是当年RISC的出现,很多人都认为CISC要退位了,然而用户的黏性(惯性)还是CISC,一直延续到今天。虽然今天英特尔的CISC和RISC的界限不那么明显,但这个过程足以说明,科技产业更依赖商业模式和市场推广,而不是某项看起来很牛的技术。
而英伟达也在重复英特尔当年做的事,那就是构建自己的生态圈,这就是CUDA。CUDA即Compute Unified Device Architecture,是NVidia利用GPU平台进行通用并行计算的一种架构,它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员可以利用C言、OpenCL、Fortran、c++等为CUDA架构编写程序。

包括CUDA自家编译器所采用的C语言扩展、OpenCL应用程序接口、Fortran甚至C++等都可以运行在CUDA架构之上,自从2006年发布CUDA,英伟达已经构筑了超级强大的生态圈,CUDA无处不在。

在合作伙伴上,英伟达全面开花。谷歌的TENSORFLOW黏性十足,说不定类似当年的Windows。
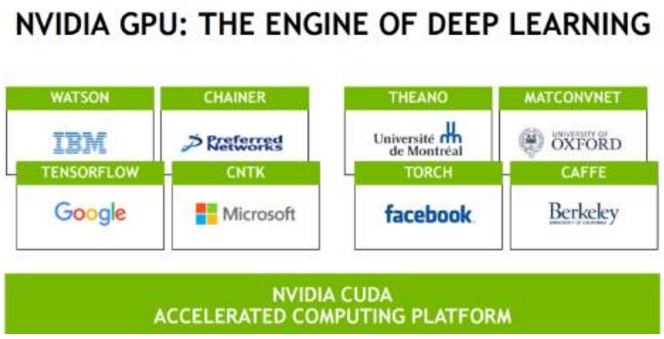
汽车领域,英伟达也是最先发力,现在无论嵌入式,还是汽车还是HPC,英伟达的CUDA无处不在,这对后来者是一个很难突破的障碍,尤其是编程难度较高的FPGA。毫无疑问,未来5-10年内GPU都是加速器主流。