3月20-21日,由佐思产研、佐智汽车主办,地平线、TTTech、魔智、海信网络科技、晶众股份、芯仑光电、PLK、中科慧眼等单位支持的2018第三届ADAS与自动驾驶国际论坛在上海银星皇冠假日酒店举办。超过400多位嘉宾参加了本次论坛,Minieye联合创始人&CEO刘国清发表了《基于FPGA平台做的车规级ADAS开发》的主题演讲。

Minieye联合创始人&CEO 刘国清
刘国清:大家下午好!我是Minieye的刘国清。今天给大家分享的是基于FPGA平台做的车规级ADAS开发。
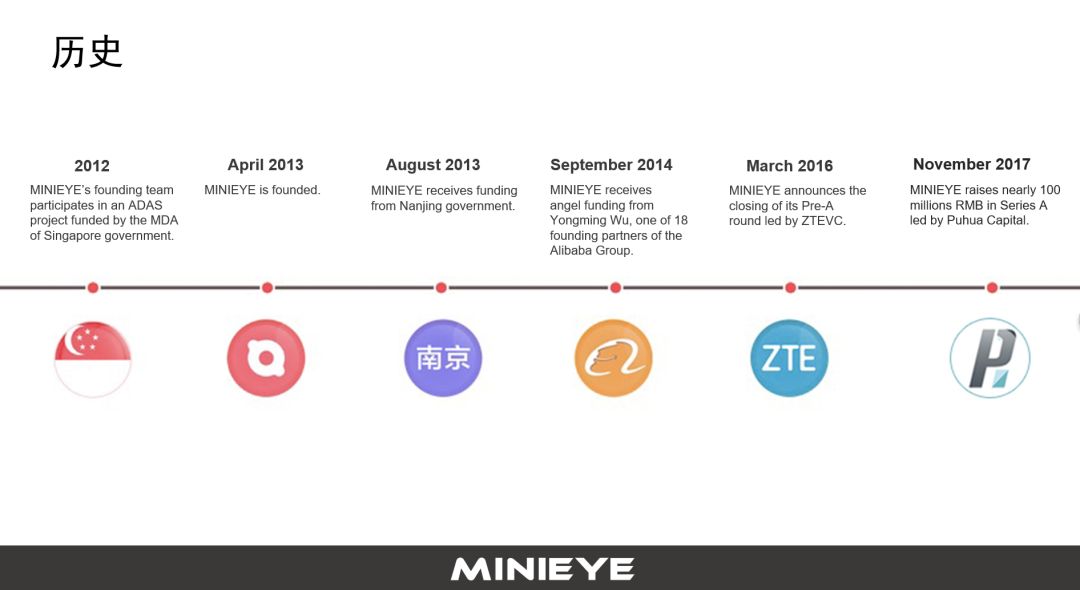
我们从2012年开始做ADAS相关研发,入行很早。2013年我从新加坡回国内成立公司运作该项目,在几轮资本的协助下,公司稳定发展。更重要的是依托政府和政策的红利,特别是最近两年法律法规的推动,无论在前装还是后装都给整个行业带来了机会。
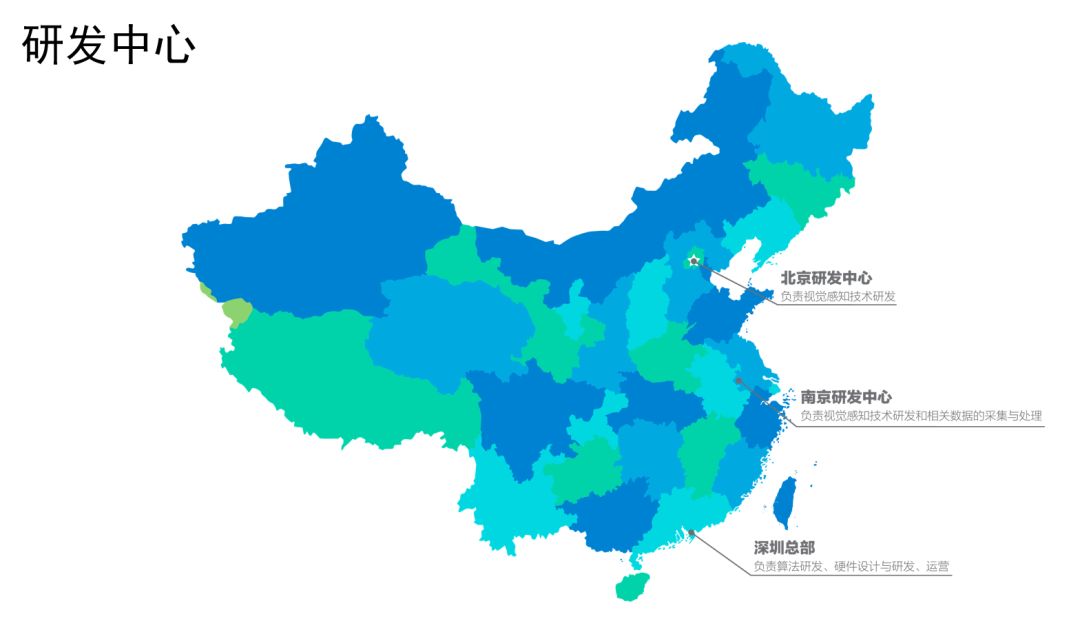
我们总部在深圳,在南京和北京设两个研发中心,北京是基于深度学习的工作,南京做应用层面研发,深圳这边除了做研发以外,还是运营的总部。
公司最开始的几个人是做视觉的,甚至还有黑客出身的,经过五年时间的发展,逐步在电子、硬件、软件、测试等方面,获得了全面和均衡的发展。经过五年持续的努力,得到了行业内外科技圈的认可。
前装的ADAS产品,去年我们跟很多车厂做项目和技术交流之后,发现需求有很多共通点。车规级是一个门槛,是起步级的。除了车规级以外,车厂还希望低成本、够便宜,功能还要可定制化。有些客户需要把它跟液晶仪表、HUD等打通,做一些人机交互。
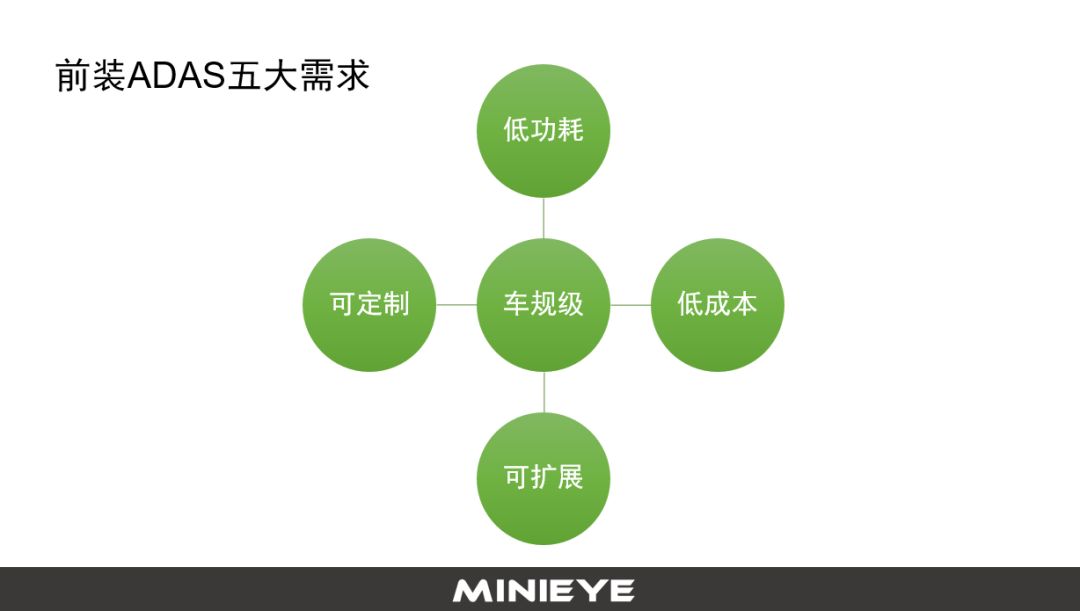
定制化是比较常见的,这要求我们做算法、硬件平台,各种接口要够灵活,另外还要可拓展,并且低功耗。而我们跟图像相关的计算,哪怕就是一个往内存或者硬盘里写的问题,做的不好还会占用计算资源,功耗很高。
基于FPGA的平台,可以满足前装的ADAS需求。现在很多FPGA的车规级芯片每年出货量都是在KK级,相对于GPU或者是其他的定制化芯片,这个量级保证了采购成本在很合理的区间。
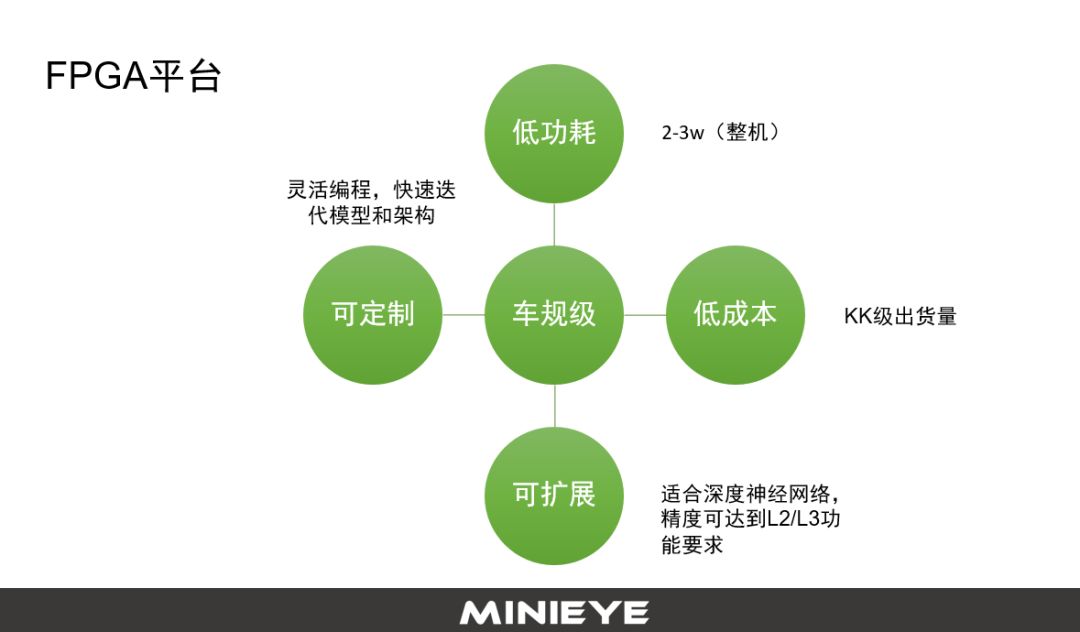
另外一块是功耗,FPGA整机功耗小于3w,按照目前的前装项目,这个功耗可以接受。FPGA有一个特点是可编程的。我们知道在智能驾驶、人工智能都涉及到了深度神经网络,它在快速迭代发展,每个月都有新的进展和网络结构、模型出来。
目前像GPU、FPGA,以及现在很多大公司、创业公司在做的针对神经网络的专用芯片,这都是能够为深度学习服务的。GPU第一功耗很高、第二太贵,第三它不适合在终端上做运算。FPGA要领先一代,功耗相对于GPU更低,而且从架构和逻辑上来讲更适合去做,从这个角度它可以很好满足车厂或者一些Tier 1客户的需求。
另外可扩展,能够把感知从满足L1的要求提升到L2,甚至提升到满足L3。而我们基于深度学习,架构可定制、可编程灵活,可以兼容新技术、更复杂内容,协助更好满足车厂对于L2、L3的要求。
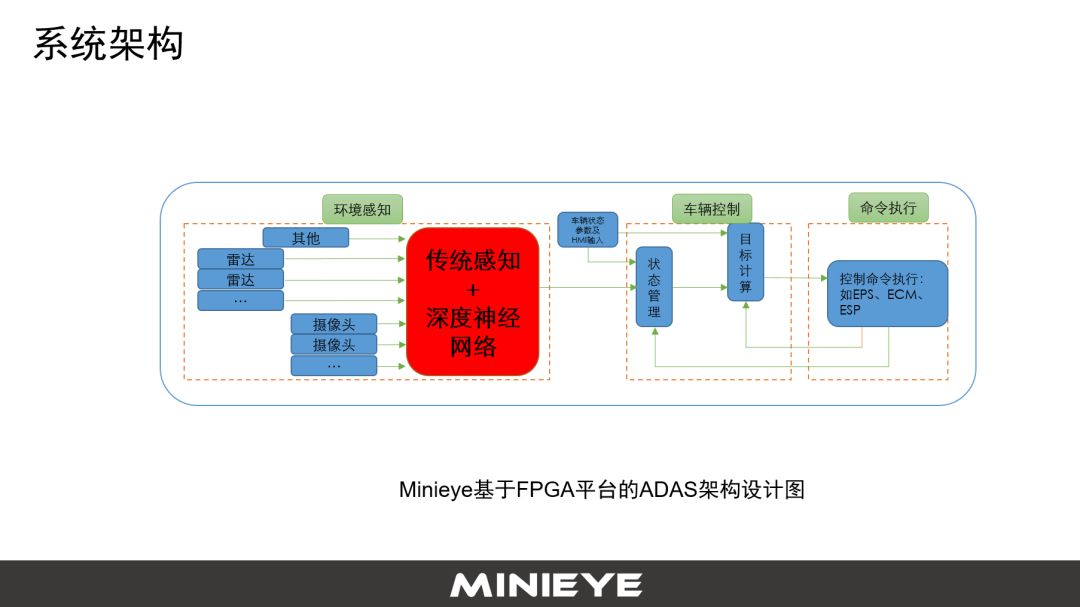
第二部分讲基于FPGA做ADAS系统开发的问题。首先是系统架构,传感器有视觉、LIDAR、雷达,基于这些感知数据做感知的算法和融合。有两种做法,一种是单独识别每一个传感器的数据,比如说摄像头识别出来车在哪?人在哪?路在哪?雷达识别出来障碍物在哪?LIDAR识别出来点云的障碍物在哪?基于这些结果来做。
另外一种是在L3以上,摄像头甚至GPS相关的原始数据,先做融合后做感知,基于融合直接改动,这种方式可能对于L3、L4、L5场景更适用一点。
红色的区域(下图)是感知模块,传统感知+深度神经网络,深度神经网络很强大,但实际上是机器学习比较流行的或者比较新的一类技术,也有很多创新。
不是说深度神经网络一定就比传统的感知算法要好,这里面列了几个关于传统感知算法和深度神经网络的比较。传统感知算法先对数据做预处理,然后做Feature transform(特征转换)。但做人体检测、行人检测就有问题,对边际信息更强的Feature就会识别更好。
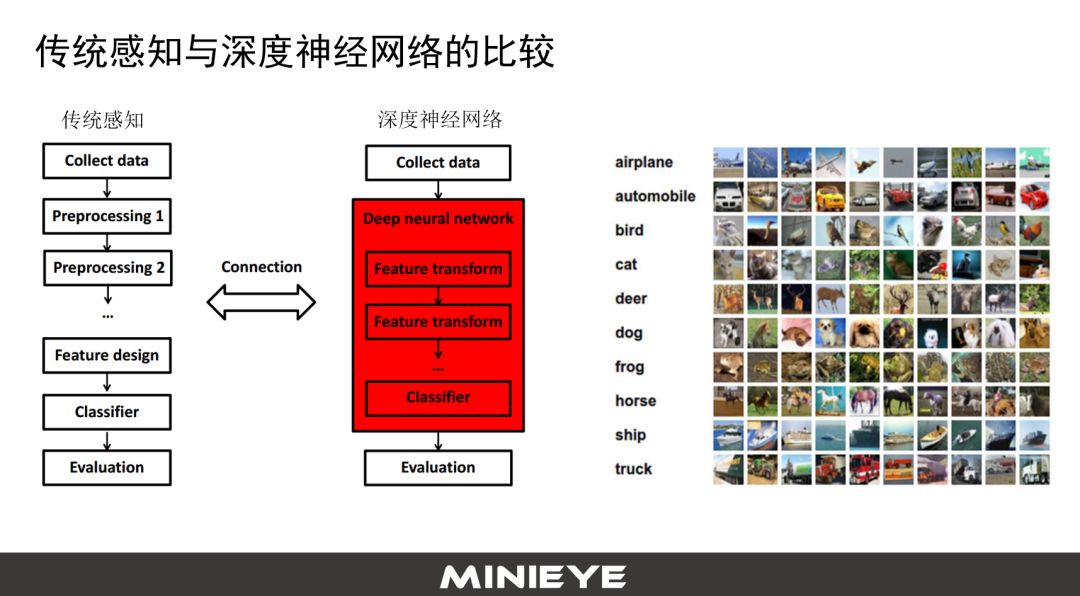
深度神经网络有一个很重要的特点叫端对端,把中间很多过程全部封装在一个箱子里面,包括Feature Design。Feature这时候不需要工程师按照经验设计,它可以从数据里面学出来。
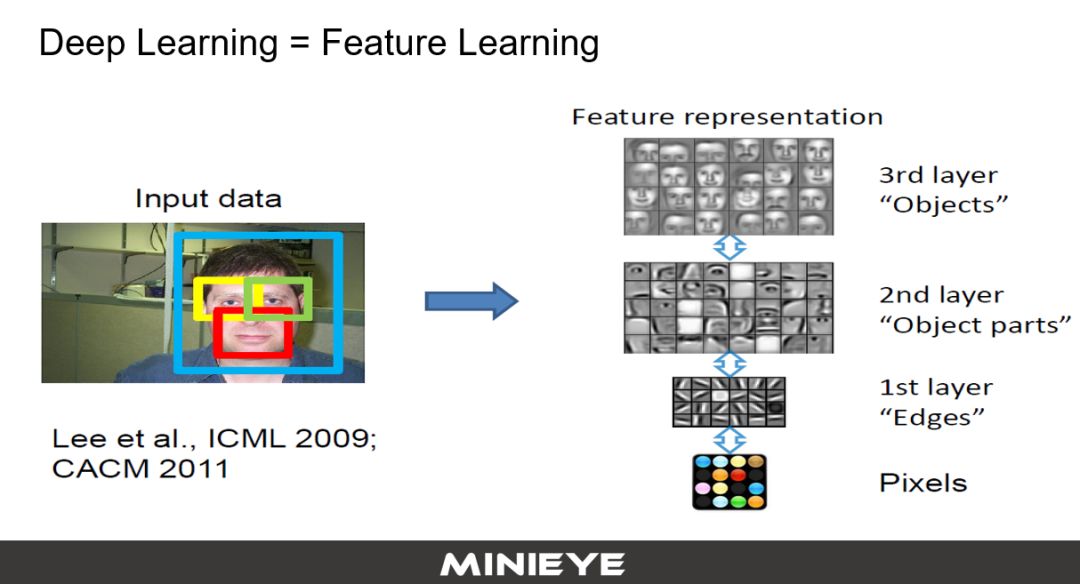
所以业界里面有一种说法,Deep learning Feature learning,学习出来的结果抽象,完全看不懂,也没有关系。以前我要去识别羊驼,要做各种设计,现在可以通过谷歌爬虫,爬一百万张羊驼的照片,借助经典的CNN神经网络,几天就能学习出来(羊驼识别系统)。
传统感知与深度神经网络相比,神经网络具有可迁移性。举个例子,比如现在用的是A摄像头,整个数据和训练模型都是基于A摄像头做的。这时候客户想用另外一款B摄像头,则完全可以基于A摄像头采集的数据,生成另外的数据,再用B摄像头采集数据做特征复用。
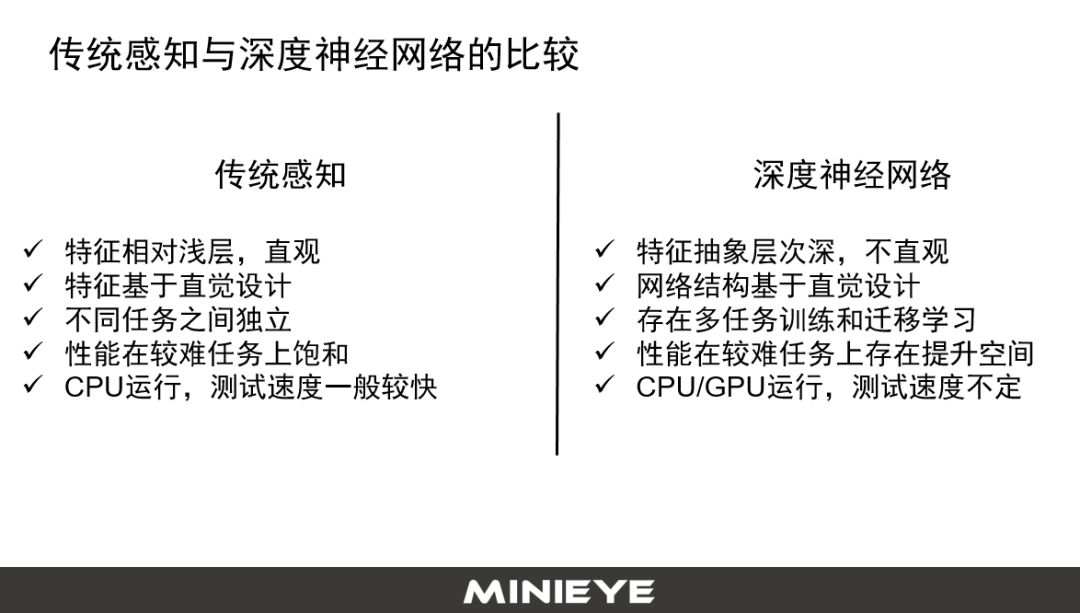
传统感知的特点是有很好的物理含义,它的整个特征是浅层的,基于直觉设计,不同的任务之间独立。它的计算资源相对于深度神经网络有很大的优势,对于功耗、计算力的要求会更低一点。
深度神经网络的Feature(特征描述)是学出来的,抽象层次深,人无法理解。它的网络结构多,任务之间可互相地做迁移的学习,但它最大问题是计算复杂度非常大。因此,传统感知算法跟深度学习各有所长,所以在我们的系统架构里采用传统感知算法和深度学习融合的方式。
如果要把基于部分使用深度学习的系统实现真正的产品化,放在面积比较小的计算力有限的FPGA平台,功耗要低、价格要便宜,这对技术研发有一系列的挑战。
首先我们提出了ThiNet,让整个神经网络变的更瘦,计算复杂度变的更低,存储更少。这主要牵扯两块核心技术,第一个是剪枝,去年计算机视觉全球最好的一个ICCV公开技术,大家感兴趣可以去搜一下,而且是开源的。

它的优势是可以对大网络进行缩减。举个例子,用大家最熟悉的神经网络为例,按照标准串完之后有一百个通道,通过对网络架构做裁减,把一百个通道降低到三十个甚至是二十个通道,而带来的精度损失可能只有千分之一。
这可以帮助我们在产品化过程追求性能和效率之间的平衡。我完全愿意付出千分之一的精度损失,来节省十倍甚至几十倍的计算资源,这意味着本来要在30美金、50美金芯片上做的事情,在几美金芯片上就可以实现。
在超级量化里可以做到8 bits量化,同时精度衰减控制在客户和我们可接受的范围内。目前通过网络压缩可以完成四种任务,检测、分类、回归、分割。这四种任务基本上满足了L1—L3里面所有感知的需求。
下图左边的架构就是我们刚才提到的ThiNet架构,右边是我们跟国外一些同样做网络压缩的一些方法的比较,可以看出来无论是在存储、缩减和计算能力的提升上,我们都是有优势的。同时我们在精度保持上仍然做的很好。

Minieye第二个要做的事情也很有用,也有比较高的技术门槛。虽然可以通过一系列的方法把深度神经网络架构变的更精简,但是它相对于传统感知,在计算复杂度上有量级上增加。
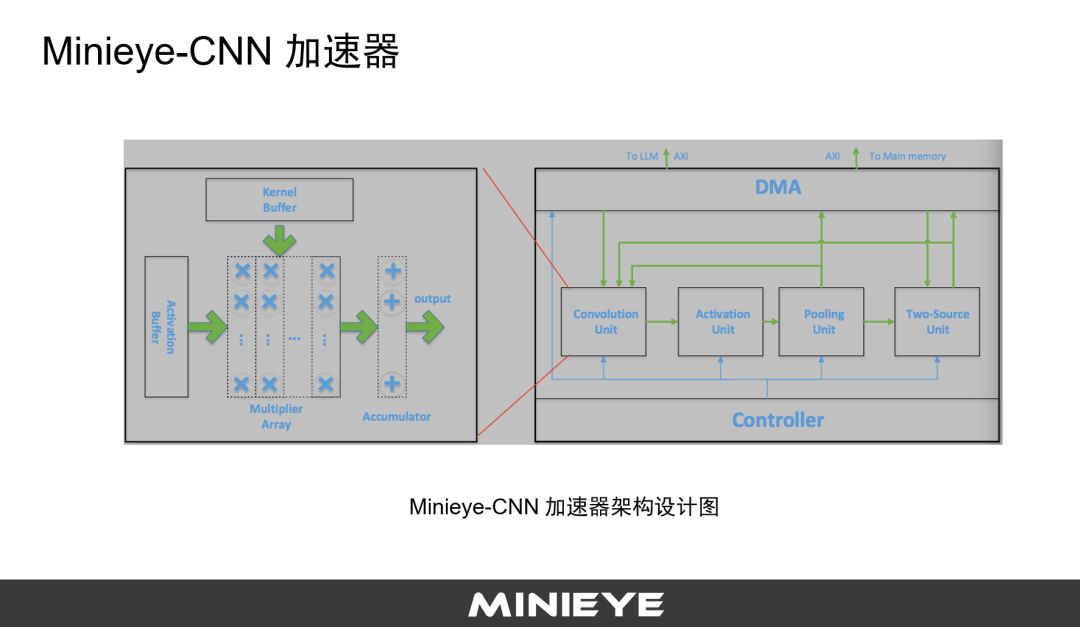
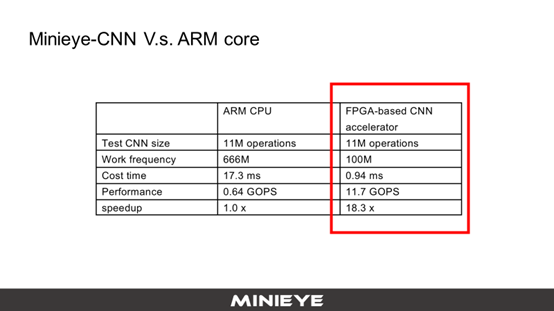
为了解决这个问题,我们在FPGA平台上开发了一个Minieye-CNN加速器,这是加速器的架构设计图。基于这样一个架构设计图,在同样的一个网络结构,在ARM的CPU上,同样的模型上,速度可以提升18倍,我们的计算性能从0.64提升到了11.7 GOPS,提升非常明显。
做前装车规级产品还有一点特别重要,就是系统测试。为了通过测试,整体数据需覆盖非常广,按照天气、光、路面、车道线、行人、车辆等,我们分成了很多不同维度,不同维度可以做交叉。
我们既有对于不同模块的单元测试,也会有系统数据库测试,我们每天都有很多车在外面跑,采集大量数据。Minieye在南京有一帮很苦逼的兄弟,每天在标注和处理数据,70%的数据用来迭代,另外30%做数据库级别的测试。为了能够更好地满足车厂对于ADAS产品的需求,在硬件在环也做了很多工作,同时还有路测,这必不可少。
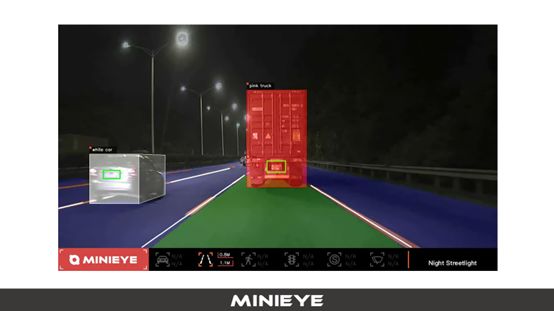
下图是我们基于现有FPGA平台实现的功能,可以看到行驶区域的分割,车辆的识别、车道的识别,尾灯、车牌,甚至对于一些场景的理解,在隧道入口、出口、白天、夜晚、路灯、信号灯、标志牌等等,目前的标志牌只做了限速牌。
我们目前的产品现在已经在多款乘用车和商用车定点,最快今年第三季度可以SOP。希望我们基于FPGA平台做的这样一套车规级ADAS产品能够有机会和各位业内同行合作和交流,我今天的报告就到这里,谢谢大家!