
自动驾驶必须用激光雷达,如果激光雷达成本足够低的话,ADAS也需要用激光雷达。基于摄像头的ADAS和无人驾驶系统,或者说以摄像头为核心的ADAS和无人驾驶系统局限很多。
首先是FOV的问题。
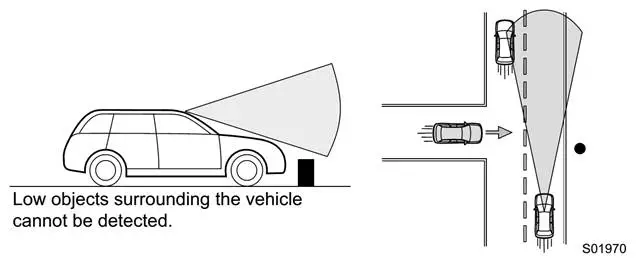
为了保证有足够远的探测距离,FOV的角度不能太大,这就导致车辆横向有非常明显的盲区。一般CMOS传感器配的镜头FOV不超过76度,超过76度就可以算广角镜头,广角镜头在近处有明显的失真,超过120度就算鱼眼镜头,图像边缘有严重的失真。一般AEB的FOV在45度到52度之间。
双目会好很多,全球最好的双目系统是日本斯巴鲁的Eyesight,第二代Eyesight的FOV是25度,第三代是35度。为了保证具备同样的探测距离,第三代Eyesight的基线长度从30厘米增加到35厘米。
为了解决FOV的问题,特斯拉和沃尔沃提出了三目Trifocal。

上图为沃尔沃的三目系统,FOV视角分别是140度、45度和34度。特斯拉是150度、50度和25度。似乎完美解决了FOV的矛盾,但是没那么简单。首先是鱼眼镜头变形严重,需要矫正失真,一般是采用插值法矫正,失真不可能100%矫正,图像质量也会出现下降。再有边缘区像素会有丢失,任何插值法都无法弥补这个丢失。最后这需要耗费大量的运算资源。再者是三个镜头的位置,特斯拉和沃尔沃都采用上二下一的设置。45度或50度的主镜头自然要居中,鱼眼和窄视角镜头分列中心线两侧,都不在中心线上,这就导致视角覆盖偏向一侧,还需要用算法校正。最后三个摄像头会有重复信息,需要采用滤波器过滤,一般会用扩展卡曼滤波器,这必然导致信息质量的下降,增加算法的复杂性,增加成本。
三目系统依然会有近距离盲区。
其次是低速的问题,摄像头系统特别是单目系统,在车辆本身低速和相对低速情况下表现很差,对突然出现的静止目标或缓慢移动目标(一般是行人)基本无效。一般纯视觉的FCW系统最低运行速度是时速30公里,Mobileye的说明书有明确指出,

Mobileye也指出了另一种低速FCW称为UFCW,但误报率太高,所以很少使用。一般Mobileye提到FCW都是指时速30公里以上的FCW。加上毫米波雷达融合数据后,最低运行时速可以下降到10-15公里。这些都是指车辆识别,对行人识别要求速度更高。

Mobileye明确指出时速50公里上行人识别才工作。
为何需要如此高的速度?
这就要说说单目摄像头的基本理念了。首先机器视觉主要针对动态目标识别,特别是汽车领域,静态目标通常都是树木,建筑物等,优先识别动态目标如车辆、行人、自行车、电动车等。有一点需要特别指出,识别目标不是最终目的,汽车上机器视觉的最终目的是计算出车辆与障碍物之间的距离,识别目标只是这个环节上的一环。而激光雷达无需任何目标识别,就能够提供最准确,360度覆盖面的距离信息。如果激光雷达成本下降到视觉系统2倍的成本,那么深度学习(目前绝大部分深度学习都是图像识别)将失去意义。
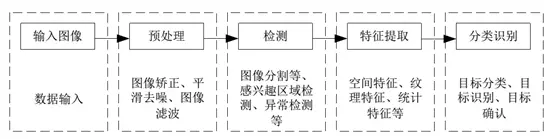
上图为机器视觉的处理流程,其主要过程为输入图像,对输入的图像进行预处理,预处理的方法主要有图像矫正、平滑去噪、图像滤波等,预处理之后的图像对其进行 ROI 区域检测或者异常检测等,对于已经检测出来的区域进行特征提取分类识别等。
第一步要将运动目标从背景图中分割出来,这也是最难的一步。目前有多种方法,但没有一种是通用的。最常见的三种方法是光流法,帧间差法和背景差法。
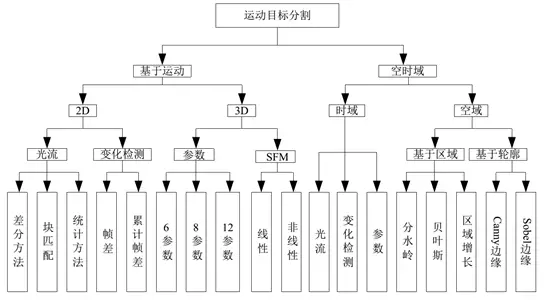
基于运动目标分割又分为 2D 与 3D。在基于运动的 2D 分割方法中可以分为基于光流不连续的分割方法和基于变化检测的分割方法。光流不连续的分割方法主要是依于图像像素的位移或者光流,由差分方法,块匹配,统计方法组成。使用模板匹配方法计算像素点的近似速度。 Spoerri在找到光流场之前使用运动边界的检测。 Overington使用不连续光流变化去检测静态场景运动目标。变化检测避免了光流法中微分梯度的计算,由帧差法和累计帧差法组成。 3D 的运动分割中主要由参数法和 SFM 法组成, SFM 法主要用于 3D 场景以及刚性运动的假设。参数方法只能假设刚性运动的分段场景。参数法主要由 6 参数, 8 参数以及 12 参数。 SFM 方法主要由线性法和非线性方法组成。
考虑到实时性和成本,目前都采用了帧差分法,这种方法最早提出,对运算资源消耗最少,最容易达到实时性,缺点就是低速下表现很差。
所谓帧差法,就检测相邻帧之间的像素变化。帧差法的基本思想是:运动目标视频中,可以根据时间提取出系列连续的序列图像,在这些相邻的序列图像中,背景的像素变化较小,而运动目标的像素变化较大,利用目标运动导致的像素变化差,则可以分割出运动目标。帧差法可以分为两帧差分法跟三帧差分法。
两帧差分法就是将视频采集到时序列图像的相邻两帧图像进行差分。对相邻的两帧图像进行差分可以在任何具有复杂的图像特征(例如,纹理特征、灰度均值等)上进行。因此, 只要明显区别与背景的运动物体均可检测出来。根据给定的阈值对差分结果二值化,若差值图像大于给定阈值,则认为该像素点是前景目标中的点,并将该像素点作为运动目标的一部分,若差值图像小于给定阈值,则认为该像素点属于背景目标点,从而将运动目标从背景目标中分割出来。图像进行阈值分割之后通常都带有噪声,因此使用形态学滤波的方法对噪声进行衰减。衰减噪声后得到的图像运动目标会存在一些空洞,需要进行连通性处理,最后才可得判别目标。阈值设定太低,检测不到目标。设定太高,会被检测为两个分开的物体。同时对于比较大的,颜色一致的运动目标,如白色大货车,帧间差分法会在目标内部产生空洞,无法完整分割提取运动目标。
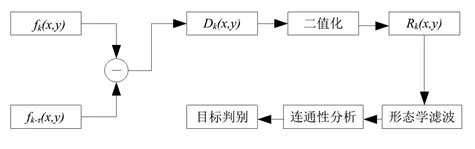
上图为两帧差分法流程
为了解决两帧差分法的缺陷,人们又提出三帧差法法。
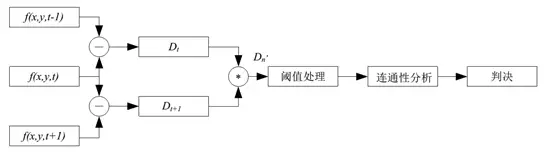
上图为三帧差分法流程
三帧差分与两帧差法原理相同,效果略好,但需要大量运算资源,速度通常是两帧差法的5倍,一般两帧差法(15Fps)的平均时间为25毫秒。
背景减除(差分)法基本思想是利用背景的参数模型来近似背景图像的像素值,将当前帧与背景图像进行差分比较实现对运动区域的检测,其中区别较大的像素区域被认为是运动区域,而区别较小的像素区域被认为是背景区域。背景减除法必须要有背景图像,并且背景图像必须是随着光照或外部环境的变化而实时更新的,因此背景减除法的关键是背景建模及其更新。针对如何建立对于不同场景的动态变化均具有自适应性的背景模型,减少动态场景变化对运动分割的影响,研究人员已提出了许多背景建模算法,但总的来讲可以概括为非回归递推和回归递推两类。背景差分法对光照变化和抖动异常敏感,而车肯定是要抖动的,且背景差分法对运算资源需求多,实时性不佳,比较适合室内监控,汽车领域并不适合。
光流法是目前热门,在适当的平滑性约束条件下,根据图像序列的时空梯度估算运动场,通过分析运动场的变化对运动目标和场景进行检测与分割。通常有基于全局光流场和特征点光流场两种方法。最经典的全局光流场计算方法是L-K(Lueas&Kanada)法和H-S(Hom&Schunck)法,得到全局光流场后通过比较运动目标与背景之间的运动差异对运动目标进行光流分割,缺点是计算量大。特征点光流法通过特征匹配求特征点处的流速,具有计算量小、快速灵活的特点,但稀疏的光流场很难精确地提取运动目标的形状。总的来说,光流法不需要预先知道场景的任何信息,就能够检测到运动对象,可处理背景运动的情况,但噪声、多光源、阴影和遮挡等因素会对光流场分布的计算结果造成严重影响;而且光流法计算复杂,很难实现实时处理。
对单目来说,要想获得距离信息,必须先识别目标。
要提供目标距离信息,首先要对目标进行框图分割,而分割和识别是一体的,不识别无法准确分割。
图像识别简单分为两大类,一类是基于词包模型的图像识别,一类是基于深度学习的图像识别。
Csurka等首次将“自然语言处理”领域的 BoVM(bag of words)模型引入到图像分类领域。就是将图像类比为文档,将图像信息用若干单词表示,最终用单词的频率直方图表示图像。首先,将一幅图像待检测的特征点或者特征区域用特征描述算子对其进行描述。将提取的特征算子采用机器学习的方法进行训练获得用特征频率表示的视觉单词组成的视觉词典。最后,通过对不同类别的视觉直方图进行学习,便可以获得学习模型。在测试环节,提取待测试图像的特征,获得待测试图像的视觉单词直方图,与上述获得的学习模型与待测试图像的频率直方图进行匹配,获得分类识别结果。由此可见,将 Bag-of-Word 应用到图像分类模型上通常需要三个步骤:1) 特征检测与描述, 2) 视觉词典的构建, 3) 分类器。
视觉词包模型(bag-of-words)相对比其他模型最大的优势在于适用于大部分的应用场合,可以简单直观地把图像表示成直方图呈现出来,这样就可以使图像分类识别问题转化成普通模式识别问题,所需运算资源少。但是,视觉词包模型也有一些缺点: 1)使用特征用视觉单词直方图表示,在这个转化的过程中,丢了特征的位置信息,在一些需要位置信息的研究中,如前方突然掉落的物体,突然出现的行人,这个方法明显是不适合的; 2) 在视觉词包模型建立的在单词与单词之间相互独立的基础上,但是有些情况,单词与单词之间是互相有联系的,如连续的视频,因此,视觉词包模型在这种情况下使用,是造成识别结果较差。
词包模型实际上相当于只包含了一个卷积层和一个汇聚层,且模型采用无监督方式进行特征表达学习,而卷积神经网络则包含了更多层的简单、复杂细胞,可以进行更为复杂的特征变换;并且其学习过程是有监督过程的,滤波器权重可以根据数据与任务不断进行调整,从而学习到更有意义的特征表达。从这个角度来看,卷积神经网络具有更为强大的特征表达能力,因此它在图像识别任务中的出色性能就很容易解释了。
分割并识别后是估算距离,单目估算距离主要是根据像素大小,这种方法准确度不高。
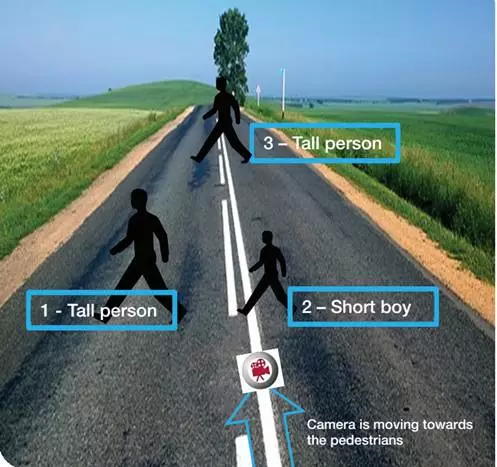
由于距离因素,行人3和行人2的像素大小是非常接近的,但行人2和行人3与车辆距离距离差别很大,单目无法得出准确的距离。

上图为基于SFM的距离估算。这可以看作是稀疏光流法,缺点是运算资源消耗多,且对光线变化和抖动比较敏感。
双目与单目区别有几点,首先双目是测量距离而非估算。
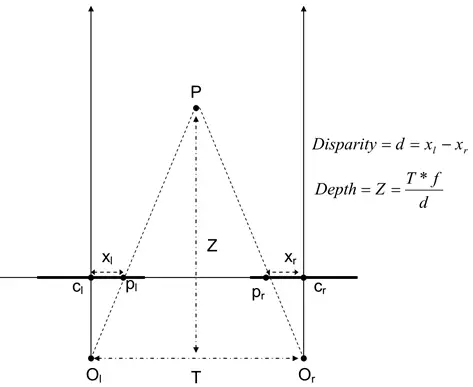
上图为双目的距离计算公式,准确度比单目要高得多。
双目与单目区别的第二点是双目可以在不识别目标的情况获得深度(距离)数据。
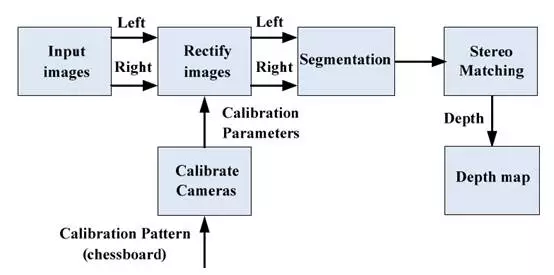
上图为双目的典型工作流程图。双目最后输出的是一张深度图。
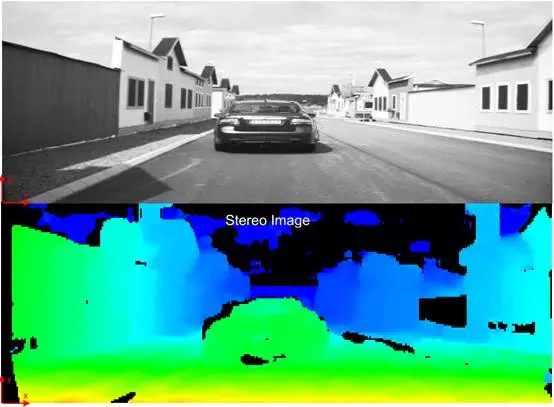
用颜色深浅来代表距离。双目虽然不需要识别目标,但是双目需要级化分割(Segmentation),常使用的算法有Belief Propagation和Mean Shift。双目最关键的环节在立体匹配。
双目输出深度图无法直接用于诸如AEB之类的功能,和单目一样,还需要将运动目标分割出来。对每一个像素点都做视差运算需要耗费大量运算资源,而最主要的还是正前方的图像区域的视差,所以也有先做ROI限定。
对视觉系统来说,无论单目还是双目,都需要运动目标分割和追踪,这就离不开帧间差法,而正是帧间差法导致视觉系统有两个严重缺陷,一是低速状态下,可能无法检测到障碍物,特别是移动缓慢或静止的障碍物。二是对突然由运动转为静止的障碍物基本无效或需要较长时间来检测和识别,如前车掉落的物品。
对激光雷达来说,运动目标的分割要简单得多。
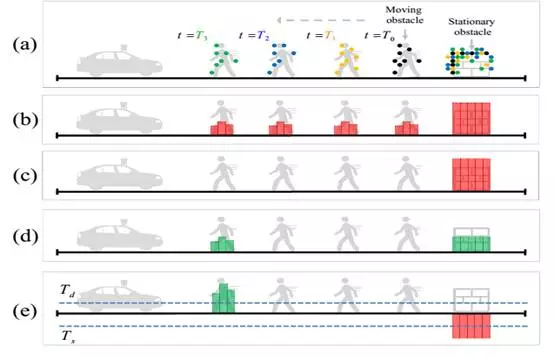
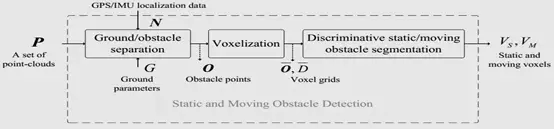
与动态物体比,静态物体捕获的点云数自然要多。用VOXELGRID滤波器可以轻松将动静目标分离,同时利用激光雷达强度成像的特点,还可以轻松识别大部分静态目标,如车道线,道路边缘,建筑物,草地,树木,路灯等。
时速低于30公里的无人驾驶系统也需要配备激光雷达才算安全。考虑到单目视觉系统的探测距离,其对应的最高时速一般不超过65公里,双目则可以达到90公里。所以无论是高速公路的无人驾驶还是城市道路的无人驾驶,激光雷达都是必须的。