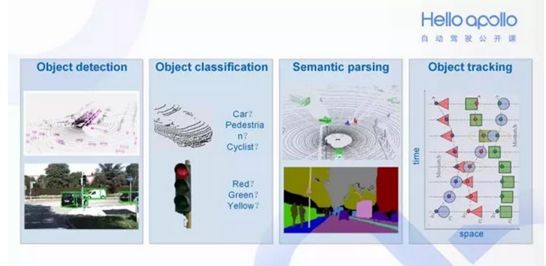
在 Apollo 中感知模块有以下几个职能:探测目标(是否有障碍物)、对目标分类(障碍物是什么)、语义分割 (在整帧画面中将障碍物分类渲染)、目标追踪 (障碍物追踪)。
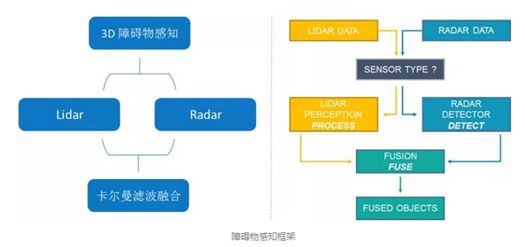
Apollo系统使用了毫米波雷达和激光雷达的融合的方式做环境感知,摄像头只负责红绿灯的检测。而毫米波雷达最大的作用是提供目标的运动速度,可以说目标识别基本是靠激光雷达完成的。
最初在2016年10月,百度与清华联合发表了论文Multi-View 3D ObjectDetection Network for Autonomous Driving ,地址https://arxiv.org/pdf/1611.07759.pdf,论文以激光雷达与摄像头融合的方式做目标识别,不过在2017年5月百度发表的论文Vehicle Detection from 3DLidar Using Fully Convolutional Network,地址https://arxiv.org/pdf/1608.07916.pdf,这篇论文里已经放弃与摄像头融合。在2017年10月,加入毫米波雷达融合。2017年11月,苹果发表论文,VoxelNet: End-to-EndLearning for Point Cloud Based 3D Object Detection,也是只用激光雷达识别目标,并且与百度和清华Multi-View 3D ObjectDetection Network for Autonomous Driving做了对比,显示出单纯用激光雷达效果更好。究其原因,第一是激光雷达数据处理速度比摄像头要快,时间同步很有难度,两者还需要坐标统一;第二是摄像头对光线太敏感,可靠性低,远距离尤其明显;第三,百度在最新版的Apollo系统里(Apollo 2.0)使用激光雷达与毫米波雷达融合的方案。这也是全球独一无二的,用毫米波雷达与激光雷达融合的方案,体现了百度的创新能力。
激光雷达物体识别最大的优点是可以完全排除光线的干扰,无论白天还是黑夜,无论是树影斑驳的林荫道,还是光线急剧变化的隧道出口,都没有问题。其次,激光雷达可以轻易获得深度信息,而对摄像头系统来说这非常困难。再次,激光雷达的有效距离远在摄像头之上,更远的有效距离等于加大了安全冗余。最后,激光雷达的3D云点与摄像头的2D图像,两者在做深度学习目标识别时,2D图像容易发生透视变形(perspective distortion)。简单地说透视变形指的是一个物体及其周围区域与标准镜头中看到的相比完全不同,由于远近特征的相对比例变化,发生了弯曲或变形。这是透镜的固有特性(凸透镜汇聚光线、凹透镜发散光线),所以无法消除,只能改善。而3D就不会有这个问题,所以3D图像的深度学习使用的神经网络可以更加简单一点。
另外,激光雷达也可以识别颜色和车道线。实际上激光雷达与摄像头没有本质区别,其最大区别除了激光雷达是主动发射激光,是主动传感器外,只是光电接收二极管不同。摄像头可以做到的,激光雷达都能够做到,只是目前激光雷达的点云密集度还不能和300万像素级摄像头比。
无人车领域对目标图像的识别不仅仅是识别,还包括分割和追踪。分割就是用物体框框出目标。对于2D图像来说,只能用2D框分割出目标,而激光雷达图像则可以做到3D框,安全性更高。追踪则是预测出车辆或行人可能的运动轨迹。

很明显,3D的分割框要比2D的有价值的多,这也是Waymo和百度都用激光雷达识别车辆的原因之一。
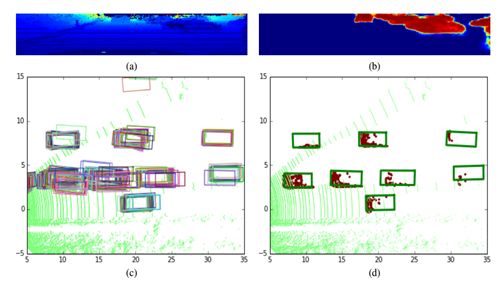
上图中,a是视觉化处理的点云图,b是经过过滤(可能是粒子滤波)的目标置信度图分布,红色代表置信度比较高。c将其2D平面化,然后将所有可能是车辆的云点都做物体框分割,最后做非极大值抑制(NMS)处理。非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。经过NMS处理后,基本就可以准确给出物体框。
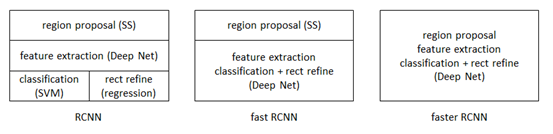
接下来就和2D图像识别类似了,将云点转换为可以使用Faster R-CNN的数据结构,再用Faster R-CNN识别。目标检测与识别领域早期为DPM,2013年11月,目标检测领域公认的大神Ross Girshick推出R-CNN,2015年4月进化为Fast R-CNN,2015年6月进化为Faster R-CNN,成为今日目标检测与识别领域公认最好的方法,也是可以完全端对端地实现。
激光雷达的目标检测与识别自然也是要用FasterR-CNN。Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是ObjectDetection领域的主流框架之一,虽然后续推出了R-FCN,Mask R-CNN 等改进框架,但基本结构变化不大。同时不乏有SSD,YOLO等新作,但精度上依然以Faster R-CNN为最好。从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
fasterRCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络RPN(Region ProposalNetworks)代替fast RCNN中的Selective Search方法。不过RPN只能针对密集化的具备张量结构的数据,而激光雷达的云点是稀疏的,因此激光雷达深度学习识别物体的关键就是如何把点云数据转换成具备张量结构的密集的视频或图像数据。
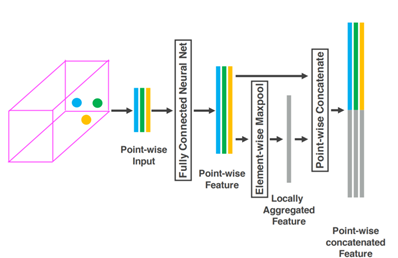
苹果就提出了一种叫VFE(Voxel Feature Encoding)的方案,就是上图。首先将点云数据转换为体素数据,基本上点云的三维数据就是体素的三维数据。根据体素所在的位置对点(点云)进行分组,把这些分组数据全部一层层堆叠起来,然后通过FCN形成有4(速度向量、X、Y、Z)张量的数据结构。
接下来看FCN,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小 (通道数,宽,高) 分别为 (4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
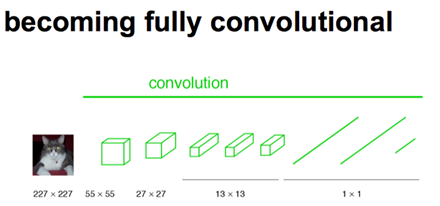
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特征图。得到高维特征的heatmap之后就是最重要的一步,也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。这就可以看做RPN了。
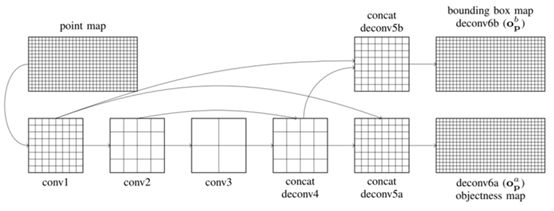
上图是百度的云点转换FCN步骤图
分类完成后,就是语义分割。图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解,判断可行驶区域)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。图像是由许多像素组成,而「语义分割」顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。语义分割有时会是最难的一部分,因为这要用到NLP自然语言处理领域的技能,而大部分玩CNN的对NLP不甚了解。
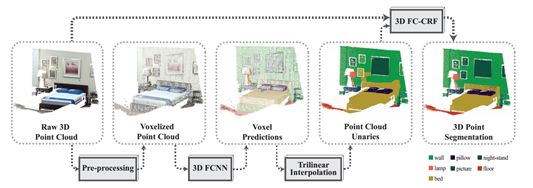
上图为斯坦福大学的激光雷达语义分割流程图,最后是用3D FC-CRF,也就是全连通条件随机场,另一种常用的方法是MRF,马尔科夫随机场。条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果。在中文分词、中文人名识别和歧义消解等任务中都有应用。
百度的语义分割主要是为了更好地理解交通场景,为行为决策提供依据。低成本的无人驾驶也可以用摄像头的2D图像做语义分割,为无人车找出可行驶区域,光线良好的情况下可以用这种低成本的方案。

上图为奔驰的语义分割图形数据集Cityscapes,比Cityscapes更知名的数据集是丰田等推出的KITTI。
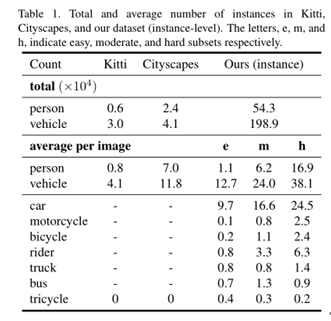
KITTI由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,用于评价目标(机动车、非机动车、行人等)检测、目标跟踪、路面分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中多达15辆车和30个行人,还有各种程度的遮挡。
Cityscapes数据集则是由奔驰主推,提供无人驾驶环境下的图像分割数据集。用于评估视觉算法在城区场景语义理解方面的性能。Cityscapes包含50个城市不同场景、不同背景、不同季节的街景,提供5000张精细标注的图像、20000张粗略标注的图像、30类标注物体。
3月8日,百度正式开放ApolloScape大规模自动驾驶数据集。ApolloScape拥有比Cityscapes等同类数据集大10倍以上的数据量,包括感知、仿真场景、路网数据等数十万帧逐像素语义分割标注的高分辨率图像数据,进一步涵盖更复杂的环境、天气和交通状况等。ApolloScape数据集涵盖了更复杂的道路状况,比如单张单张图像中最高可达162辆交通工具或80名行人 ,同时开放数据集采用了逐像素语义分割标注的方式。
Kitti,Cityscapes和ApolloScape的数据实例对比
对我国传统车厂来说,自建训练数据集恐怕是最大的难题,与百度合作是最好的选择。